Abstract
In recent years, Vision Transformer-based approaches for low-level vision tasks have achieved widespread success. Unlike CNN-based models, Transformers are more adept at capturing long-range
dependencies, enabling the reconstruction of images utilizing non-local information. In the domain of super-resolution, Swin-transformer-based models have become mainstream due to their capability
of global spatial information modeling and their shifting-window attention mechanism that facilitates the interchange of information between different windows. Many researchers have enhanced model
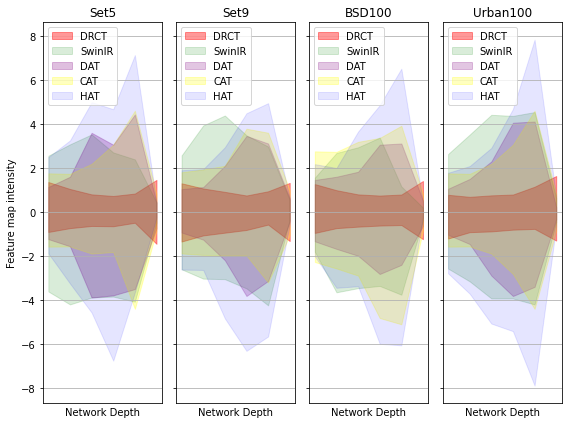
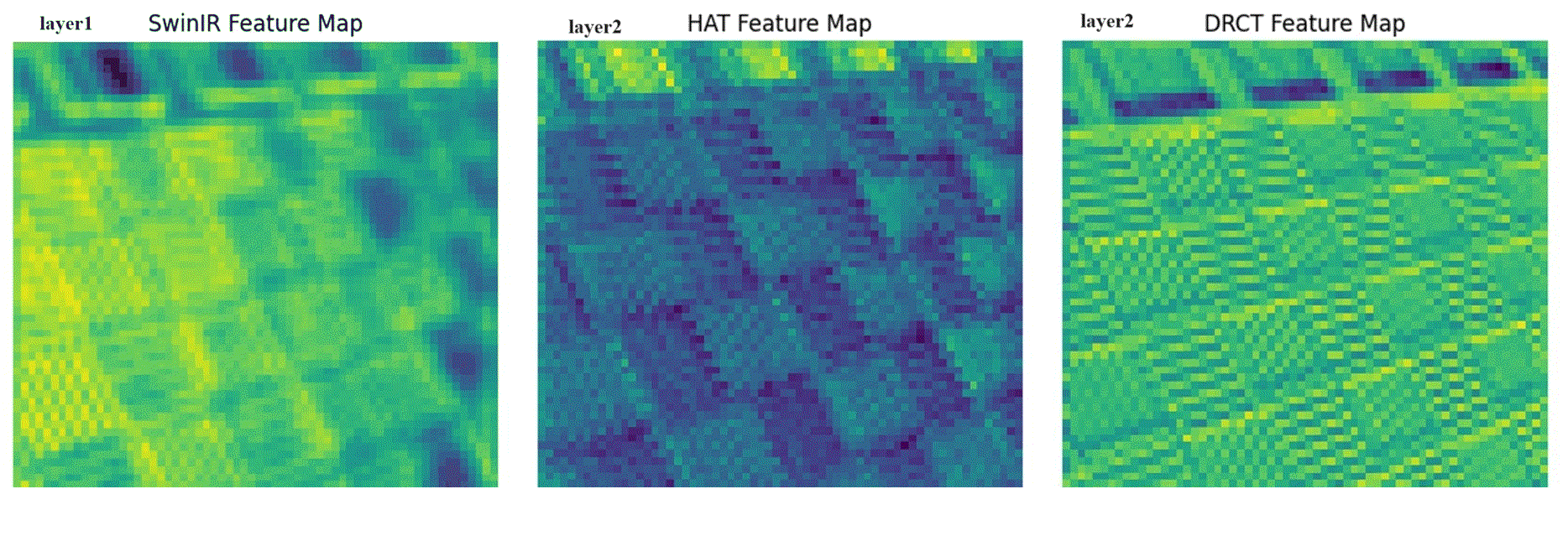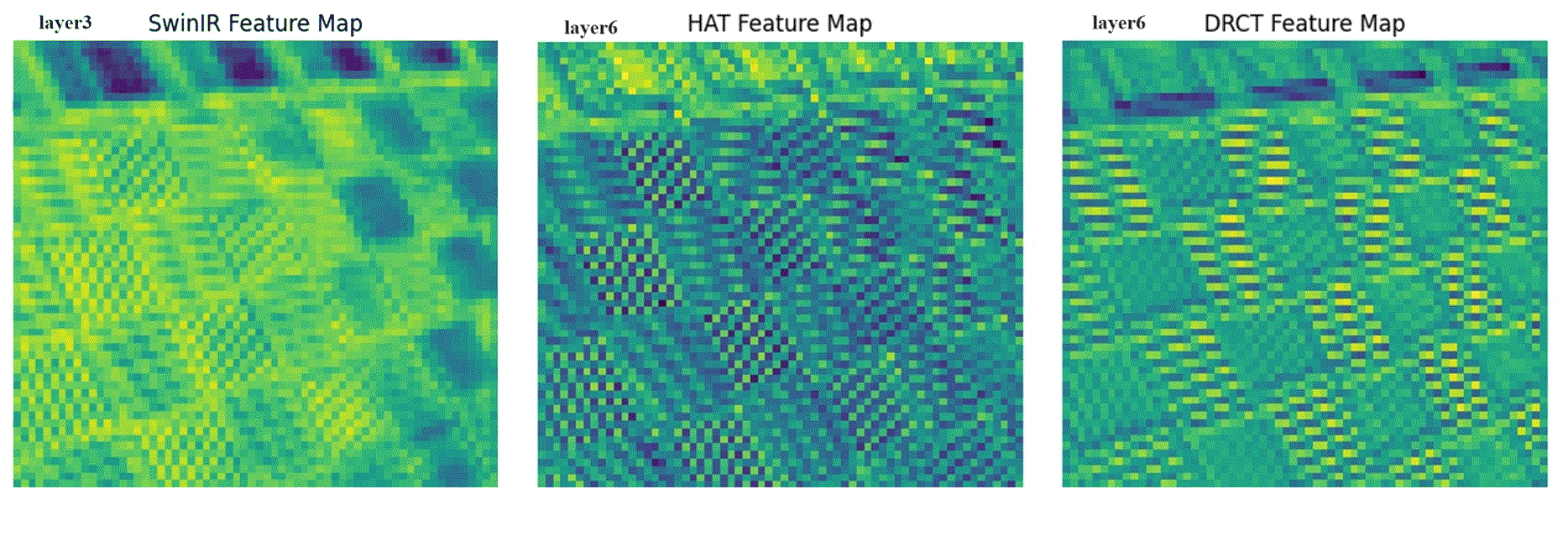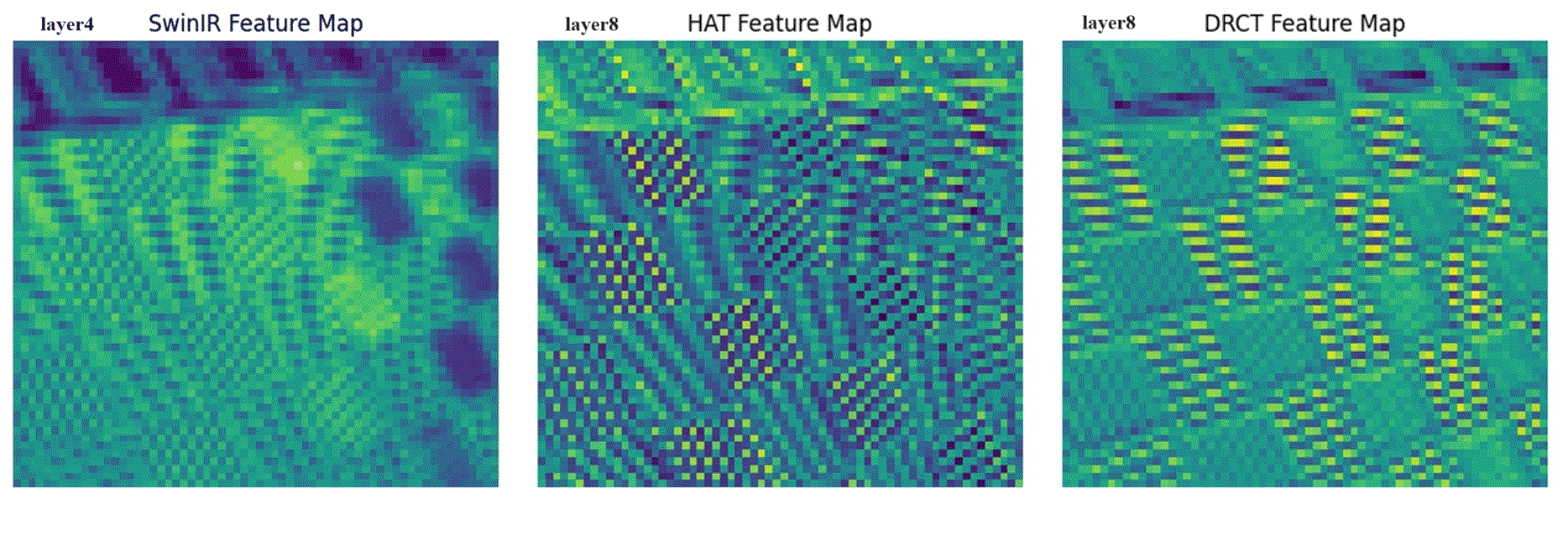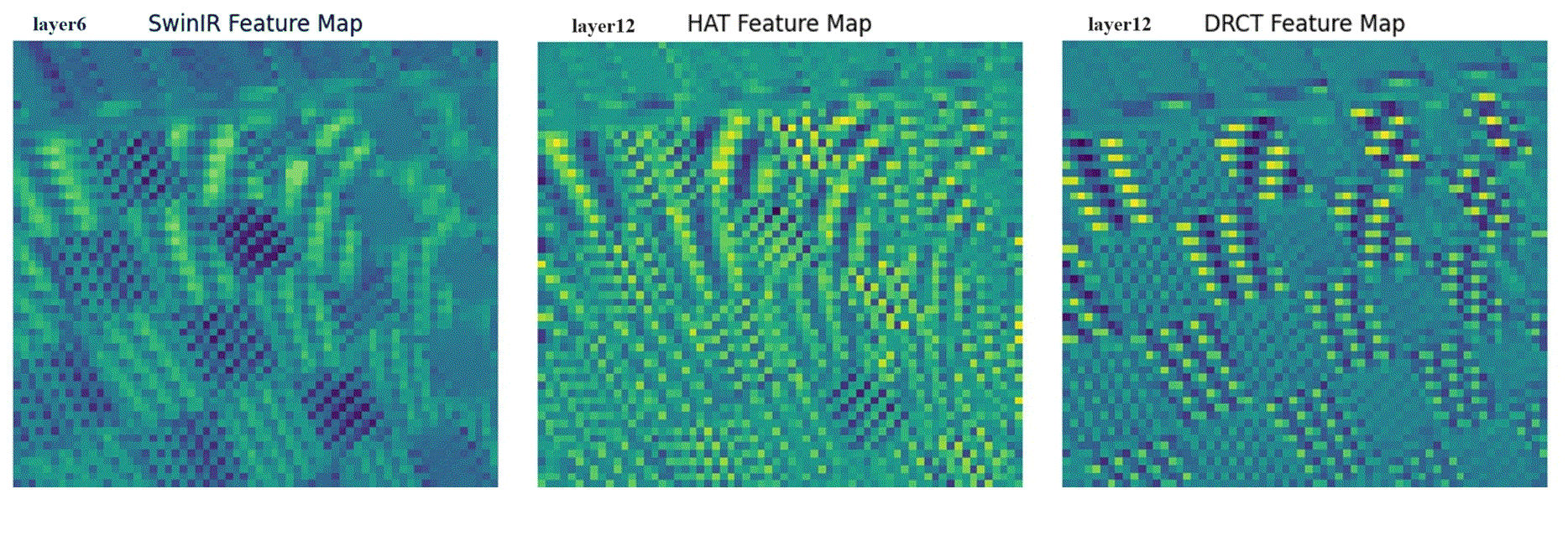
performance by expanding the receptive fields or designing meticulous networks, yielding commendable results. However, we observed that it is a general phenomenon for the feature map intensity to
be abruptly suppressed to small values towards the network’s end. This implies an information bottleneck and a diminishment of spatial information, implicitly limiting the model’s potential. To
address this, we propose the Dense-residual-connected Transformer (DRCT), aimed at mitigating the loss of spatial information through dense-residual connections between layers, thereby unleashing
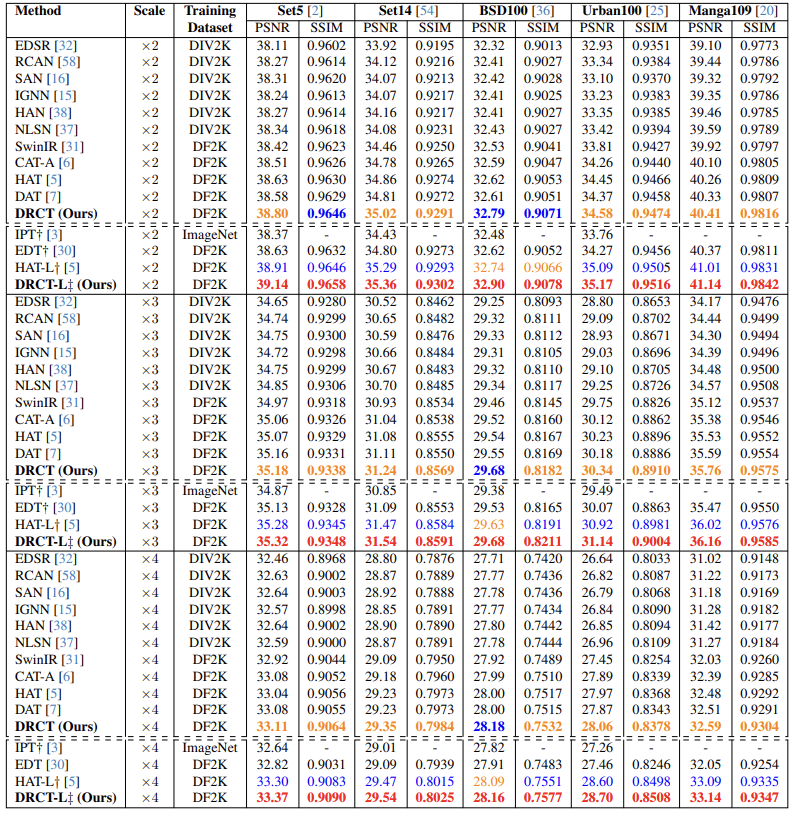
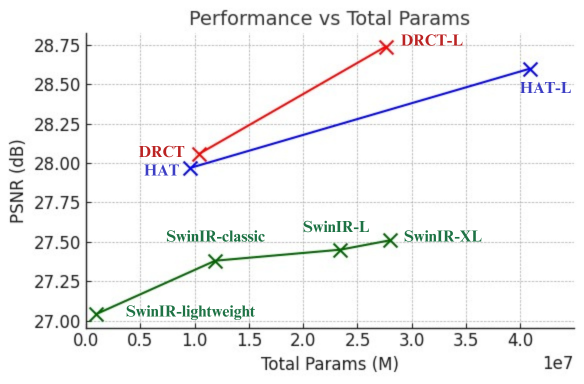
the model’s potential and saving model away from information bottleneck. Experiment results indicate that our approach surpasses state-of-the-art methods on benchmarks dataset and performs commendably
at NTIRE-2024 Image Super-Resolution (x4) Challenge.
BibTeX
@misc{hsu2024drct,
title={DRCT: Saving Image Super-resolution away from Information Bottleneck},
author={Chih-Chung Hsu and Chia-Ming Lee and Yi-Shiuan Chou},
year={2024},
eprint={2404.00722},
archivePrefix={arXiv},
primaryClass={cs.CV}
}